Updated Orientation Information in NIfTI Headers
Recently some users reported that a handful of datasets hosted on OpenfMRI contained NIfTI files with ambiguous orientation information. This issue can make distinguishing between the left and right brain hemispheres virtually impossible without some external reference (like a fiducial marker). This issue can also cause sub-optimal results and failures from some analysis software packages.
Many of the the affected datasets originated from the same source, and the subjects involved were scanned with the same basic imaging protocol. Where possible, we have re-converted the original DICOM files to NIfTI in a way that preserves the scanner-anatomical orientation information. For those subjects whose DICOM files were no longer available, we set a basic orientation (based on the imaging protocol in use at the time) that made distinguishing left from right possible; however the precise subject positioning during scanning is not known. The datasets that have either of these corrections applied are indicated in the table below.
Updated on 20 Dec 2017
|
Accession Number |
Dataset Title |
Corrected from Source DICOM |
Corrected using approximate orientation |
|
ds000001 |
Balloon Analog Risk-taking Task |
sub006, sub011, sub012, sub013, sub014, sub015, sub016 |
sub001, sub002, sub003, sub004, sub005, sub007, sub008 |
|
ds000002 |
Classification learning |
No orientation information available - leaving as-is. Use at own risk. |
No orientation information available - leaving as-is. Use at own risk. |
|
ds000003 |
Rhyme judgment |
All subjects |
|
|
ds000005 |
Mixed-gambles task |
sub004 (runs 1,3 only), sub005, sub006, sub007, sub008, sub009, sub010, sub011, sub012, sub013, sub014, sub015, sub016 |
sub001, sub002, sub003, sub004 (run 2 only) |
|
ds000006 |
Living-nonliving decision with plain or mirror-reversed text |
All subjects |
|
|
ds000007 |
Stop-signal task with spoken & manual responses |
All subjects |
|
|
ds000008 |
Stop-signal task with unconditional and conditional stopping |
All subjects |
|
|
ds000009 |
The generality of self-control |
All scans except as mentioned at right |
sub016 task001_run001 sub016 task002_run002 |
|
ds000017 |
Classification learning and stop-signal (1 year test-retest) |
All subjects |
|
|
ds000105 |
Visual object recognition |
Not at this time |
Not at this time |
|
ds000108 |
Prefrontal-Subcortical Pathways Mediating Successful Emotion Regulation |
Not at this time |
Not at this time |
| ds000177 | Magnitude Effect | Not at this time | Not at this time |
| ds000223 | Effects of mouth breathing on hippocampal activity examined by 3T fMRI | Not at this time | Not at this time |
Table 1: Datasets affected and summary of corrective actions taken.
For datasets ds000105 and ds000108, the source DICOM data are not available, and not enough information is known about the original positioning/acquisition to apply any orientation information, so we are leaving them as-is. A warning message has been placed above the download links notifying potential users to use caution when interpreting analysis results from these data sets.
What scans were affected?
Most BOLD and inplane T2w scans from the above datasets were affected. Some high resolution T1w anatomical scans were affected. This included derived data such as skull-stripped images and brain mask files. The orientation information for the derived data was also corrected, but was not re-generated from updated files.
What was wrong with the files?
The NIfTI header fields that store the orientation information, including the mapping from the in-file voxel indices to anatomical coordinates, were zeroed out. Specifically:
qform_code set to 0, pixdim[0] = 0
quatern_b, quatern_c, quatern_d all equal to 0
qoffset_x, qoffset_y, qoffset_z all equal to 0
sform_code set to 0
srow_x, srow_y, srow_z had all elements equal to 0
This problem likely arose because of the use of older software for conversion from DICOM to NIfTI, which did not properly generate and store the orientation information. Below is an example of the symptomatic (“old”) and the updated header fields from a sample file. More information about these fields can be found at: The NIfTI file format.
|
nifti_field |
nvals |
old value |
correct value |
|
pixdim |
8 |
0.0 3.125 3.125 4.0 1.0 |
-1.0 3.125 3.125 4.0 2.0 |
|
qform_code |
1 |
0 |
1 |
|
sform_code |
1 |
0 |
1 |
|
quatern_b |
1 |
0 |
0 |
|
quatern_c |
1 |
0 |
-1 |
|
quatern_d |
1 |
0 |
0 |
|
qoffset_x |
1 |
0 |
97.931519 |
|
qoffset_y |
1 |
0 |
-68.019211 |
|
qoffset_z |
1 |
0 |
-106.650566 |
|
srow_x |
4 |
0.0 0.0 0.0 0.0 |
-3.125 0.0 0.0 97.931519 |
|
srow_y |
4 |
0.0 0.0 0.0 0.0 |
0.0 3.125 0.0 -68.019211 |
|
srow_z |
4 |
0.0 0.0 0.0 0.0 |
0.0 0.0 4.0 -106.650566 |
What exactly does this mean?
A NIfTI file for a typical MRI scan stores the voxel values in an array of numbers. The coordinates for a single voxel within a NIfTI image volume can be specified as a 3 dimensional index (x, y, z) or a 4 dimensional index (x, y, z, t). In the example below, the voxel located in the nifti file at index (x, y, z) = (127, 259, 368) has the intensity value 2250 (arbitrary units).
Figure 1: Sagittal (left), coronal (middle), and axial (right) slices from a NIfTI image file with no orientation information. The cross-hairs indicate the voxel located at the (x, y, z) index and has intensity value 2250.

This information is unambiguous, and any software that supports the NIfTI file format should return the same intensity value for the same (x, y, z) in-file voxel index, as confirmed by using the nifti_tool command-line program on the same file:
dataset 'anat/sub-9022_ses-1_T1w_no_orient.nii' @ (127 259 368 0 0 0 0)
2250
The ambiguity arises when the voxels positions are interpreted in the context of some physical space, for example: the position (in centimeters) of the subject in the scanner the location (in millimeters) of a voxel in some standard co-registration template, andas being in the left or right hemisphere of the subject being examined.
The qform and sform NIfTI header fields provide the information to create mappings from the (x, y, z) voxel indices to continuous coordinates in some target space. If these fields aren’t set properly, the mapping may produce incorrect results.
In the following example, a T1-weighted data set was co-registered to the MNI-152 1mm template (Figure 2). One registration was performed with a T1-weighted image file that contained correct qform/sform information (Figure 3), and a second registrations was performed using the same T1-weighted image file with zeroed-out qform and sform information (Figure 4).
Each co-registration was performed using FSL’s flirt (v6.0/Mac) command:
Figure 2: The MNI-152 1mm template. The viewer (fslview 3.2.0/Mac) displays the left/right, anterior/posterior, and superior/inferior axis labels representing the orientation of the standard subject template.
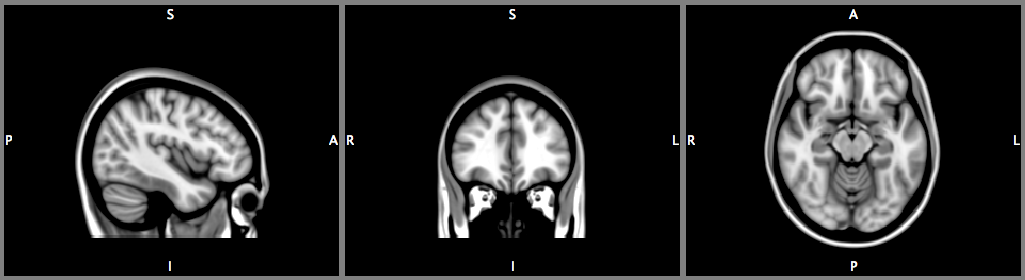
Figure 3: The T1-weighted image NIfTI file with accurate qform/sform information embedded in the NIfTI header. The arrow points to a brain structure identified in the subject’s left hemisphere using the original data. After co-registration to MNI, the structure remains in the correct hemisphere.

Figure 4: The T1-weighted image NIfTI file with zeroed-out qform/sform information embedded in the NIfTI header. The arrow points to the same brain structure identified in the subject’s left hemisphere using the original data. After co-registration to MNI, the structure is located on the incorrect hemisphere.

The corrections applied to the datasets listed in Table 1 should provide the information to accurately distinguish left from right.
All user reports and feedback are valuable and help to improve the quality of the datasets.